AI Acceleration System
Members: Joonsung Kim, Dongup Kwon, Eunjin Baek, Suyeon Hur, Minseop Kim
Motivation
In this project, we analyze the need of the current industry-hot AI applications (e.g., CNN, RNN, MANN) and provide various architecture and system solutions to efficiently accelerate them. Our current interests lie in developing highly-scalable and flexible AI acceleration systems by actively exploiting heterogeneous hardware solutions together (e.g., FPGA, ASIC, GPU, SSD).
Research
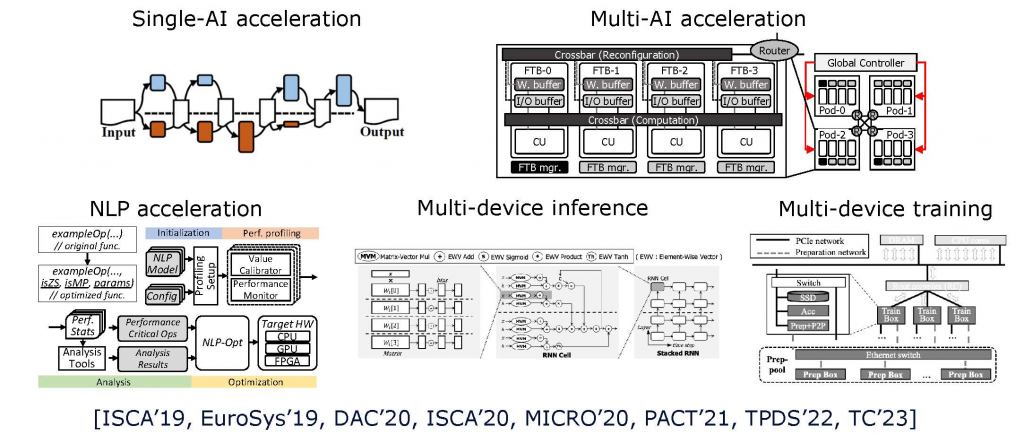
Single-AI acceleration [EuroSys’19, ISCA’19, PACT’21]. As we face an era of running AI applications everywhere, it is imperative for computer architects to provide high-performance and cost-effective computer systems to accelerate emerging AI applications as CNN, RNN, and MANN. To achieve the goals, we thoroughly analyze the emerging AI applications including state-of-the-art NLP and recommendation applications (e.g., BERT, Transformer, DLRM), split a single AI application to multiple sub-tasks, and optimize and distribute them to heterogeneous hardware components. In this way, our architecture solutions can significantly improve the performance of modern AI applications in the most cost-effective way.
Multi-AI acceleration [ISCA’20, TC’23]. Modern computer systems support many users, and each AI service gets to run many heterogeneous AI applications simultaneously (e.g., multi-tenancy cloud server, autonomous driving, and mobile system). Therefore, it is important to provide a single accelerator which can simultaneously accelerate multiple AI services in the most cost-effective way. To achieve the goal, we design a novel multi-NN execution computer architecture solution which can split multiple heterogenous AI applications to many co-location friendly subtasks and dynamically schedule them to keep maintaining the accelerator’s utilization at the maximum.
Multi-device AI processing [MICRO’20, DAC’20, TPDS’22]. A fundamental challenge to develop an AI acceleration system is to make it support the ever-increasing size of AI applications and data. But, as a single computer’s scalability is limited, computer architects have come to orchestrate multiple computer systems to enable an extreme-performance AI inference and training. To overcome the issue, we propose various methods to parallelize modern AI application’s inference and training, and provide highly scaling computer architecture solutions which consist of CPUs, GPUs, ASICs, and FPGAs
Flexible AI processing. Existing AI acceleration systems have been designed to support their specific target AI applications and behaviors. Therefore, once such application-specific accelerators are fabricated, they cannot run other kinds of AI applications or suffer from significant performance degradations. To resolve the issue, we are currently designing a highly-flexible AI acceleration system which can run highly heterogeneous applications, but also dynamically configure its architecture to improve the current target application’s performance.
Process-in-Memory Architecture [MICRO’22]. The computing capabilities of AI services come at the cost of extreme memory-driven energy consumption. Existing studies adopt process-in-memory (PIM) architectures, which offload computations to the memory arrays; however, they fail to maximize the potential benefits due to their 2D-driven solutions. To mitigate the issue, we design a 3D NAND Flash-based PIM architecture, a dedicated retraining framework, and a compiler to realize the 3D-driven PIM architecture.
Software release
-
- NLP-Fast: https://snu-hpcs.github.io/NLP-Fast/
- 3D-FPIM: https://github.com/SNU-HPCS/3D-FPIM/
Publications
- STfusion: Fast and Flexible Multi-NN Execution using Spatio-Temporal Block Fusion and Memory Management
Eunjin Baek, Eunbok Lee, Taehun Kang, and Jangwoo Kim
IEEE Transactions on Computers (TC), Apr. 2023 - 3D-FPIM: An Extreme Energy-Efficient DNN Acceleration System Using 3D NAND Flash-Based In-Situ PIM Unit
Hunjun Lee*, Minseop Kim*, Dongmoon Min, Joonsung Kim, Jongwon Back, Honam Yoo, Jongho Lee, and Jangwoo Kim
55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct. 2022 - DLS: A Fast and Flexible Neural Network Training System with Fine-grained Heterogeneous Device Orchestration
Pyeongsu Park, Jaewon Lee, Heetaek Jeong, and Jangwoo Kim
IEEE Transactions on Parallel and Distributed Systems (TPDS), Jan. 2022 - NLP-Fast: A Fast, Scalable, and Flexible System to Accelerate Large-Scale Heterogeneous NLP Models
Joonsung Kim, Suyeon Hur, Eunbok Lee, Seungho Lee, and Jangwoo Kim
IEEE International Conference on Parallel Architecture and Compilation Techniques (PACT), Sep 2021 - TrainBox: An Extreme-Scale Neural Network Training Server by Systematically Balancing Operations
Pyeongsu Park, Heetaek Jeong, and Jangwoo Kim
IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct. 2020 - Scalable Multi-FPGA Acceleration for Large RNNs with Full Parallelism Levels
Dongup Kwon, Suyeon Hur, Hamin Jang, Eriko Nurvitadhi, and Jangwoo Kim
ACM/ESDA/IEEE Design Automation Conference (DAC), Jul. 2020 - A Multi-Neural Network Acceleration Architecture
Eunjin Baek, Dongup Kwon, and Jangwoo Kim
47th ACM/IEEE International Symposium on Computer Architecture (ISCA), June. 2020 - MnnFast: A Fast and Scalable System Architecture for Memory-Augmented Neural Networks
Hanhwi Jang*, Joonsung Kim*, Jae-Eon Jo, Jaewon Lee, and Jangwoo Kim
46th ACM/IEEE International Symposium on Computer Architecture (ISCA), June. 2019 - μLayer: Low Latency On-Device Inference Using Cooperative Single-Layer Acceleration and Processor-Friendly Quantization
Youngsok Kim, Joonsung Kim, Dongju Chae, Daehyun Kim, and Jangwoo Kim
14th ACM European Conference on Computer Systems (EuroSys), Mar. 2019
* Contributed equally